缓存雪崩、缓存击穿、缓存穿透
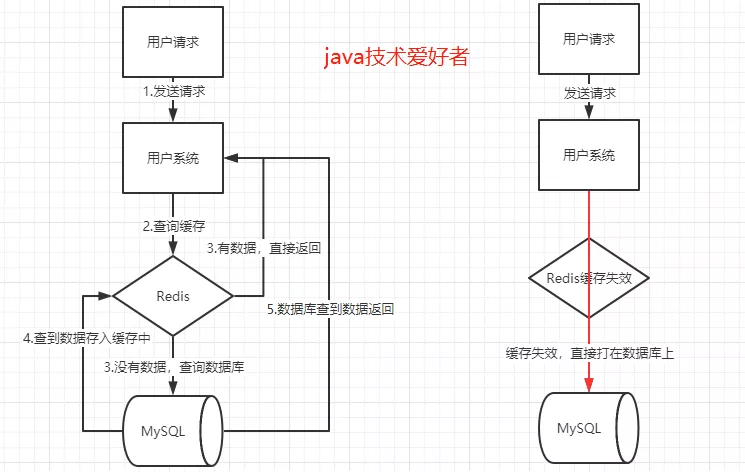
缓存雪崩
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
解决方法
- 在原有的过期时间上加一个随机值。这样就避免了因采用相同的过期时间导致的缓存雪崩。
- 使用熔断机制。当流量到达一定阀值时,就直接返回“系统拥挤”之类的提示,防止过多的请求打在数据库上。至少能保证一部分用户是可以正常使用,其他用户多刷新几次也能得到结果。
- 提高数据库的容灾能力,可以使用分库分表,读写分离的策略。
- 为了防止Redis宕机导致缓存雪崩的问题,可以搭建Redis集群,提高Redis的容灾性。
缓存击穿
其实跟缓存雪崩有点类似,缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
解决方法
- 如果业务允许,对于热点 key 可以设置为永不过期。
- 使用互斥锁,如果缓存失效,只有拿到锁才能访问数据库。
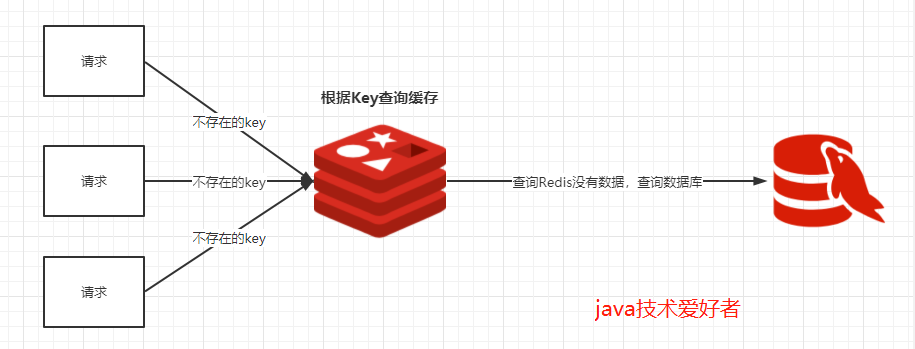
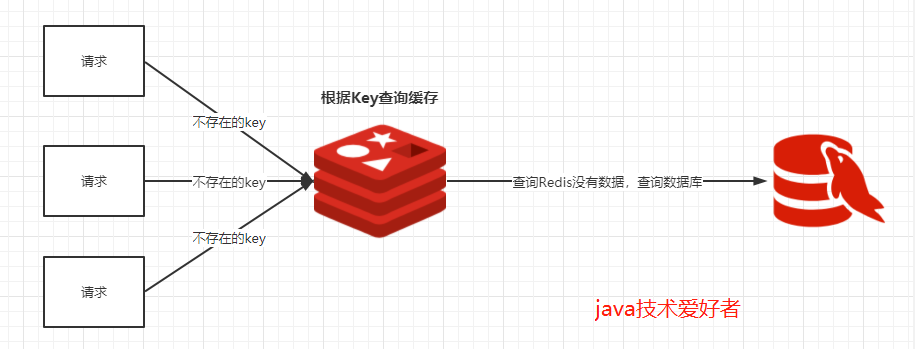
缓存穿透
我们使用Redis大部分情况都是通过Key查询对应的值,假如发送的请求传进来的key是不存在Redis中的,那么就查不到缓存,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像“穿透”了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
解决方法
- 把无效的Key存进Redis中。如果Redis查不到数据,数据库也查不到,我们把这个Key值保存进Redis,设置value="null",当下次再通过这个Key查询时就不需要再查询数据库。这种处理方式肯定是有问题的,假如传进来的这个不存在的Key值每次都是随机的,那存进Redis也没有意义。
- 使用布隆过滤器。布隆过滤器的作用是某个 key 不存在,那么就一定不存在,它说某个 key 存在,那么很大可能是存在(存在一定的误判率)。于是我们可以在缓存之前再加一层布隆过滤器,在查询的时候先去布隆过滤器查询 key 是否存在,如果不存在就直接返回。